On June 4, I organized a convening of twenty faculty, five PhD students, and two teaching and learning experts at the Kennedy School’s Ash Center to spend a day on the question that I’ve been working on for the past several months: how should we teach statistics and quantitative methods to non-specialists in a world where generative AI can automate most of the analysis pipeline?
The group was deliberately small and included faculty teaching students from undergraduate to professional to doctoral. From Harvard, we had faculty from the Kennedy School of Government, Graduate School of Education, Chan School of Public Health, and Statistics department; outside of the University we had faculty from Stanford, Wharton, CMU, Yale, Michigan, Berkeley, and Cal State LA. Some use Claude Code every day; some had read about agentic tools but never opened one. I’m grateful for financial support from the Harvard Data Science Initiative, VPAL, and SLATE which was essential to bringing everyone together.
You can read our agenda here. I organized the day around three areas: what to teach (changing curriculum), what tools to teach and how (teaching/not teaching coding), and how to get students to actually want to learn (aligning student incentives). This is a report-out of where we landed, including a tabulation of where the room agreed and disagreed.
Part 1: Three Talks
Framing the day
The first thing we did together was spend some time alone. We each took 5 minutes to write down our own assumptions about what is true about teaching statistics well; what we are afraid of losing as AI advances; and what excites us as AI advances. There was a surprising amount of consensus in what we wrote: we believe strongly that friction is a necessary condition of learning; we are worried about losing the ability to think and failing to give our students the tools to succeed in a changing world; we are excited about AI making statistical analysis something that more people can do, and letting us spend more time in class building intuition and understanding and less time on debugging code.
I then started us off by showing my experience of giving a problem set from my own causal inference course to Claude Code. Within minutes it had completed the entire assignment, completed a full set of robustness checks on the analysis, chose a cutting edge alternate identification strategy and implemented that too, wrote up a discussion of the shortcomings of each stage of the analysis, and produced a clean slide deck of the results.
The goal of showing this was to illustrate four things:
- Having the AI complete the homework was trivial. Extending it from “homework” into something closer to real work was also trivial.
- The AI didn’t make mistakes, exactly. But it made lots of decisions — defensible ones, though sometimes different ones than I might have. There were probably many more decisions than I noticed while reading its output.
- I exercised zero statistical judgment in the entire interaction.
- Based on what I teach and how I teach it, my students would not be able to evaluate whether any of it was good.
Each of these speaks to a different challenge as we figure out what to teach statistics students going forward. When every student has an army of tireless, highly proficient research assistants, the development of judgment, not mastery of mechanics, becomes the central goal. Which begs the question: we have always told ourselves the mechanics are how judgment gets built, but is that the best way to build it?
Ji Son (Cal State LA), “Why Teach Coding?”
Our first official talk of the day was from Ji Son, Cal State LA faculty, co-founder of Coursekata, and author of a very funny McSweeney’s article. For decades, Ji argued, teaching coding quietly accomplished several jobs at once: markets needed deliverables, people produced those deliverables, and education developed the people who could generate and understand that work. Generative work built up understanding — imperfectly, but as an automatic side effect of doing.
AI now produces the deliverables, so we’ve entered what she called the age of uncoupling: understanding is no longer a free byproduct of content generation. “Welcome to the first annual societal experiment,” she put it: can understanding emerge without doing? Her answer wasn’t to mourn coding but to name the three things generation used to develop for us, which we’ll now have to teach deliberately: systems thinking (understanding structure), sense-making (building causal models of the world), and metacognition (students understanding what they’re capable of becoming). She ended by suggesting that agentic AI may actually make these more important, not less.
Paul Goldsmith-Pinkham (Yale), “What Agentic AI Enables”
Paul, teacher of PhD econometrics and MBA investments, is the author of the excellent A Causal Affair. Building on his great video series on how to use Claude Code as a social scientist (which I highly recommend), Paul walked us through what is actually possible with current agentic tools. To make it concrete, he walked through a live data task on IPEDS, the sprawling federal higher-education dataset. Agentic tools, he said, “eat data munging for lunch” — a day-long slog becomes a 15-minute autonomous project. Tasks with easily verifiable output have become near-trivial, which is amazing until it isn’t. Paul spent much of his talk talking about how speeding up production does not speed up understanding. Every sped-up task generates an avalanche of new output that someone now has to check!
Paul pointed to recent work separating writing code from shipping code (Demirer, Musolff, and Yang, 2026): the authors found that there is a real productivity gain, but it lands mostly on the easy part, while the hard part of verifying, integrating, standing behind the result doesn’t shrink. And piling on still more AI to verify the AI, he cautioned, only goes so far. He closed with a set of axes to frame our thinking about what to teach: knowledge vs. actions, output vs. verification, judgment (or taste) vs. recall, and clarity vs. comprehensiveness.
Part 2: Three Breakouts
We then split into three topics, each run twice so everyone could attend two: redesigning curriculum, teaching coding, and aligning incentives toward learning. I was able to take the transcripts of each conversation and synthesize them below using AI (keeping everything theme-level and anonymous). Here are some (AI-facilitated) high-level insights:
The deepest tension never resolved: can you build judgment without doing the mechanics? One camp held that statistical and computational judgment is inseparable from the experience of generating the work: “I don’t understand what it means to understand technical material without having experience of generating technical material.” The other camp insisted you can teach the concept — what a regression is, what plot to make, wide-vs-long data — without the student executing it. The conversation really made clear that we have no evidence on what a never-coded, never-calculated graduate actually looks like in five years. More than one person named that as the question that should drive curriculum, and admitted we can’t yet answer it.
The answer depends on who you teach. Both the curriculum and coding rooms refused to give a single answer and instead split by audience: the PhD or research-track student who will publish under their own name (read the code, own the mechanics) vs. the median professional master’s student (basic fluency, direct-and-verify) vs. the ~2% who become actual data scientists. Purpose, class size, and timeline all change the prescription. An Executive MBA class is dropping point-and-click software entirely in favor of prompting, while PhD-facing courses are actually doubling down on learning code.
In the curriculum room, there was broad agreement to cut mechanical execution — syntax-heavy units, hand-calculating standard errors, “19 kinds of t-tests” — in favor of judgment, problem formulation, and the upstream work. As one person put it, “90% of the work happens before you have the dataset,” and we teach the last 10%. A nice way of capturing this is to shift the question from how do you make this plot to what plot should we make. But a lingering issue spoke to the framing remarks at the start of the day: every attempt to write an assignment that AI couldn’t simply do for the student failed. So how do we build these skills effectively?
In the coding room, the group broadly agreed coding-from-scratch is no longer the deliverable, but they did not agree on what replaces it. Is the goal to make students “critical consumers” who check the AI? One facilitator noted that checking and reading are not the same thing, and that AI may already be better at the analysis than any student we could realistically train. Others suggested moving from “coding-as-syntax” toward repositioning the coding course as the place to teach the genuinely scarce skills like problem formulation, managing context, or “selling the idea” to a human. One participant invoked a cautionary tale: an intro CS course elsewhere whose AI-assisted final projects were so poor (only a handful even ran) that the capstone was canceled and the course rebuilt around in-class, active learning. Statistics, several noted, “hasn’t had that shock yet, or maybe we just haven’t realized it.”
In the incentives room, the conversation had a lot more consensus than the other rooms. There was broad agreement that we should move assessment into the physical room — oral exams, every-class quizzes, in-class replication — and stop policing take-home work, which several had given up monitoring entirely. While this may seem easy and settled, the group wasn’t sure whether this actually deepens learning or just increases the signal of assessment (e.g., if it’s all in-class assessment, how do we know that a student has learned to an in-depth analysis). The group also discussed that the real issue is not student incentives, but instructor’s incentives. Redesign is a lot of work, and having to continuously update our courses to make sure we are reliably assessing learning is daunting. One person described the status quo as a “low-low contract” — low expectations traded for good evaluations, “the students submit AI, I grade with AI” — and noted how little pulls us toward the “high-high” alternative.
Part 3: Reflections and Post-Convening
At the end of the day I asked participants to share some reflections about what’s on their mind and what they want to work on. Here are some quotes that I found particularly interesting:
In the age of AI, being able to communicate statistical concepts is perhaps more important and oral assessments may be a useful way of building that skill. Rather than being an ends to itself, coding may still have place in a statistics class as a means to an end (e.g., pedagogical tool).
Coding may still be valuable to teach for structuring thinking / building a sense of self efficacy, but does it need to be R/Python?
Focus on collaboration between student and agent. Emphasize the benefits of coding skills beyond just getting tasks done. Better structured in class assessments. Codify what we mean by “statistical intuition” and focus on it.
Be very clear about the goals, which may range from helping students feel empowered to preparing them for the workforce. Think hard about what students want, because if we can’t get them to buy in then the path will be difficult.
A week later, I sent around a set of propositions and asked everyone to mark where they stood. There was no neutral option, so everyone had to commit! What follows is every faculty member who filled it out — 18 people (I’ve set aside the five PhD students on our organizing team for the purposes of this figure).
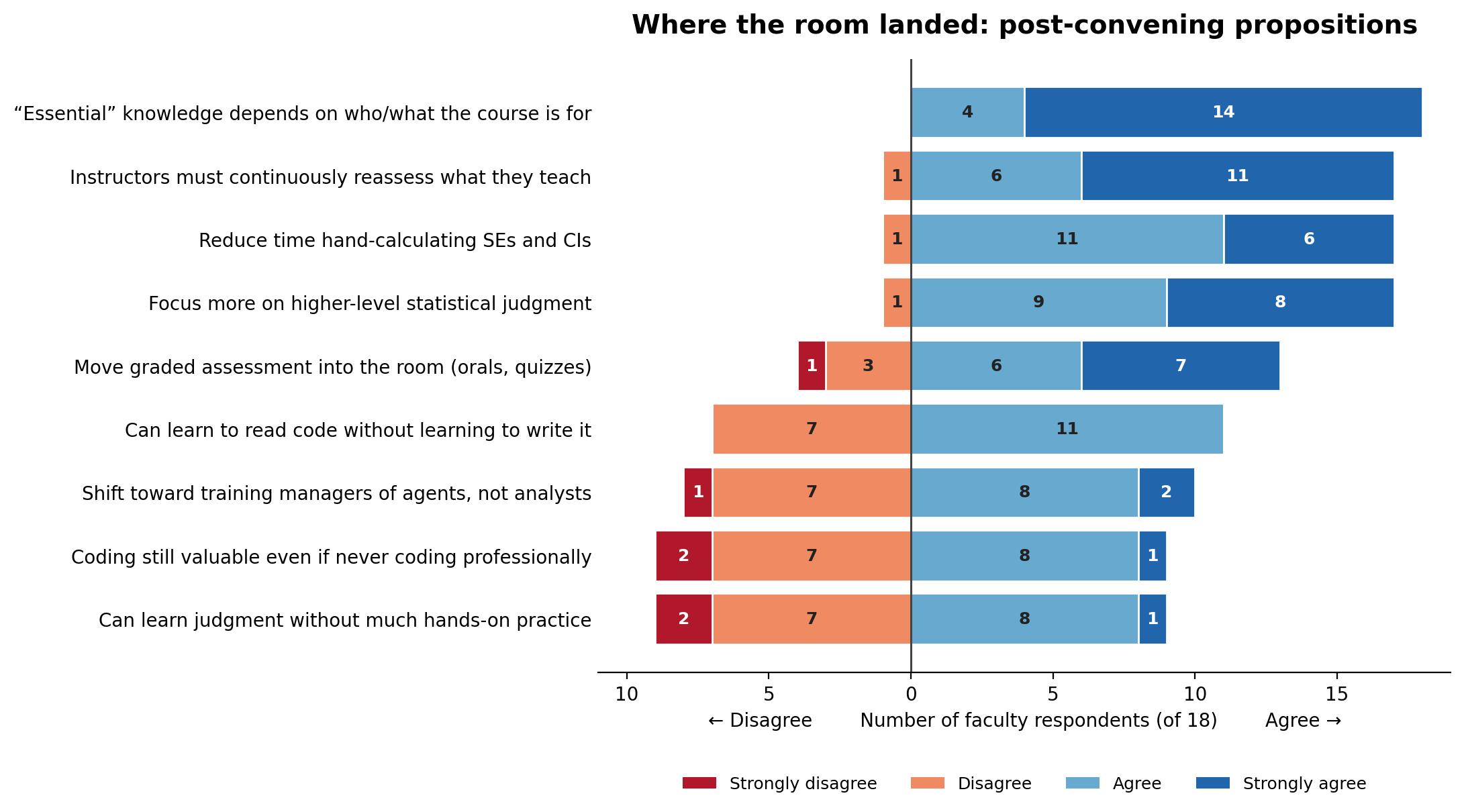
Some observations:
- The need to adapt was unanimously supported. All 18 agreed that what counts as “essential” statistical knowledge has to be conditioned on who the students are and what the course is for. That is to say, what people need to know has always been, and should continue to be, contextual.
- The move “upstream,” toward focusing on judgment instead of mechanics, was almost unanimous. Focus more on higher-level judgment; cut the time spent hand-calculating standard errors and confidence intervals; and keep reassessing what we teach as AI moves. The direction of travel is not in dispute.
- Moving graded assessment into the classroom was also popular. This claim drew broad but not universal support (13 of 17; one person abstained, noting it depends entirely on the assignment).
- The points of division all surround variants of the same question. Whether students can read code without ever writing it (11–7), whether we should train “managers of agents” rather than analysts (10–8), whether coding is still worth teaching to people who’ll never code professionally (9–9), and whether judgment can form without much hands-on practice (9–9). The last two are perfect 50-50 splits!
What’s next: Building a Community
As to be expected, the convening left me with some answers and a lot of questions. It also felt like a first step. Even though we landed in different places on a lot of the actual decisions, there was a ton of value in articulating why we diverged on certain topics and agreed on others. For that reason, I’m hoping to generate more of a community around teachers of statistics and data science to share resources, perspectives, and challenges as they come up. I think we all have pretty substantial course redesigns in our future, and I’m hopeful that we can help one another do that. To that end, if you’d like to join a community focused on these questions, please let me know here!