What follows are reflections on the past several months I’ve spent using agentic AI to help me code along a continuum ranging from code review all the way to full-blown Anthropic-take-the-wheel vibe coding. Some of the things I’ve attempted (in ascending order of coolness):
- Take a gradebook and divide students into groups of three or four, stratified by their performance on the midterm exam (for a two-stage exam);
- Use the GABRIEL Python library to extract information on participation grades and policies on generative AI, and classify each along a spectrum;
- Extend the functionality of an MCP server to query a massive database of published research in various ways, as part of a project on making rigorous research more accessible to policymakers;
- Build a capability within our PingPong platform to let chatbots query the content of class recordings to better answer student questions;
- Construct an entire personal productivity system in Obsidian that helps me structure my day, stick to my goals, keep track of urgent emails, and reflect on whether I’m getting what I want out of my days (one day I’ll write about this; it’s awesome!).
Depending on the task, I either have a lot of knowledge about how to do it myself (the two-stage exam sorting) or very little (extending the functionality of PingPong). And, reader, that continues to matter quite a bit in terms of the experience of using these tools and the quality of their output.
Some observations, impressions, and predictions:
1. I do not think anyone will be writing code within the year
Reviewing code? Sure. Debugging issues to feed into a new development push? Absolutely. But these models are simply too effective at producing high-quality code and — crucially — setting up tests to evaluate the code they write to make hand-typing code efficient in any context I can think of. If someone is working with sensitive data an LLM can’t touch, they will create dummy data to write the code against and then test the written code on the actual dataset.
You can see this happening in the AI tools themselves. Cursor, a very popular AI-powered IDE, usually looks like this (that guy isn’t usually there):
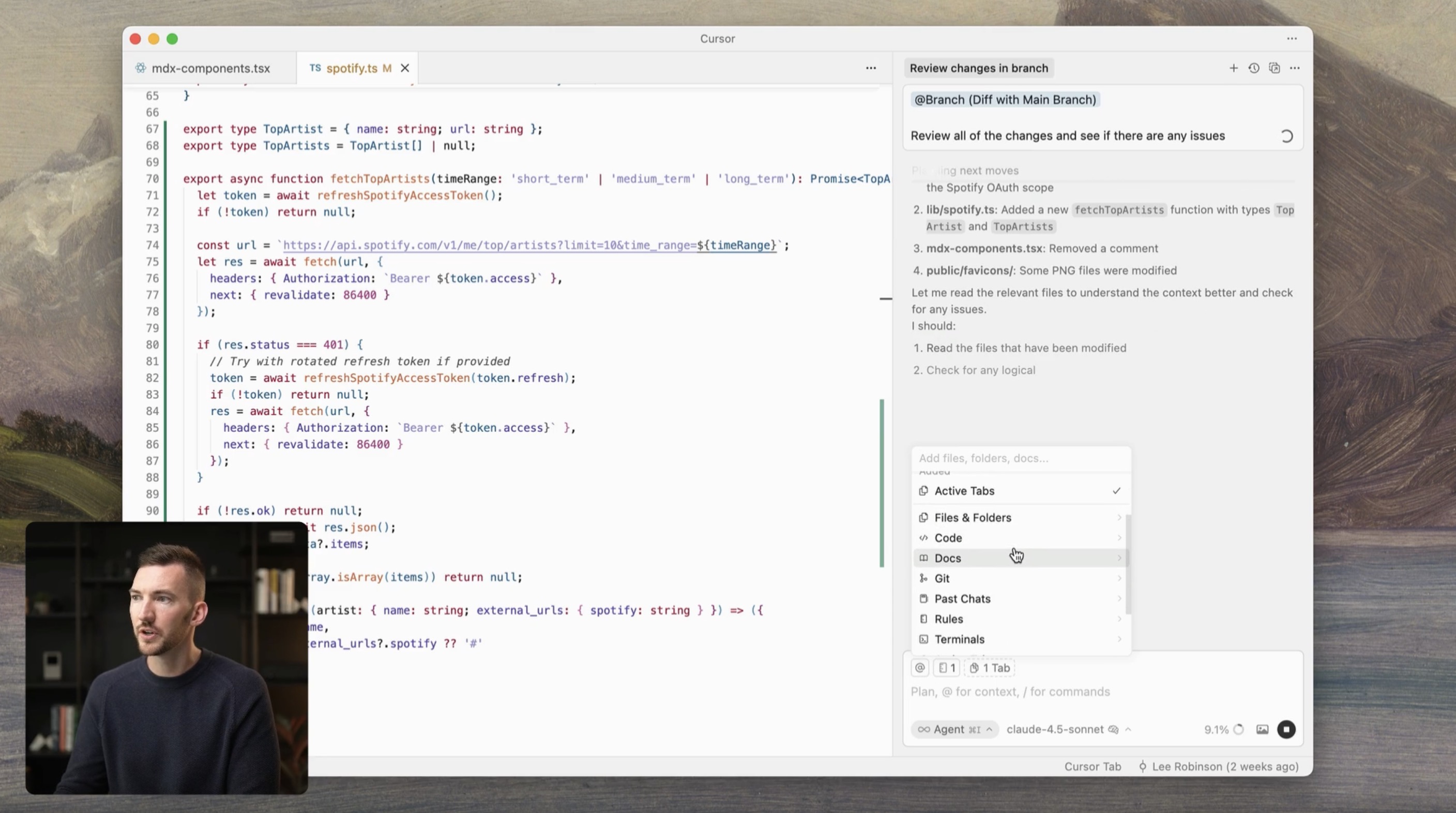
The code is front and center, with the helpful agent on the side, editing and helping you out.
Here’s Cursor 3, which was unveiled on April 2, 2026:
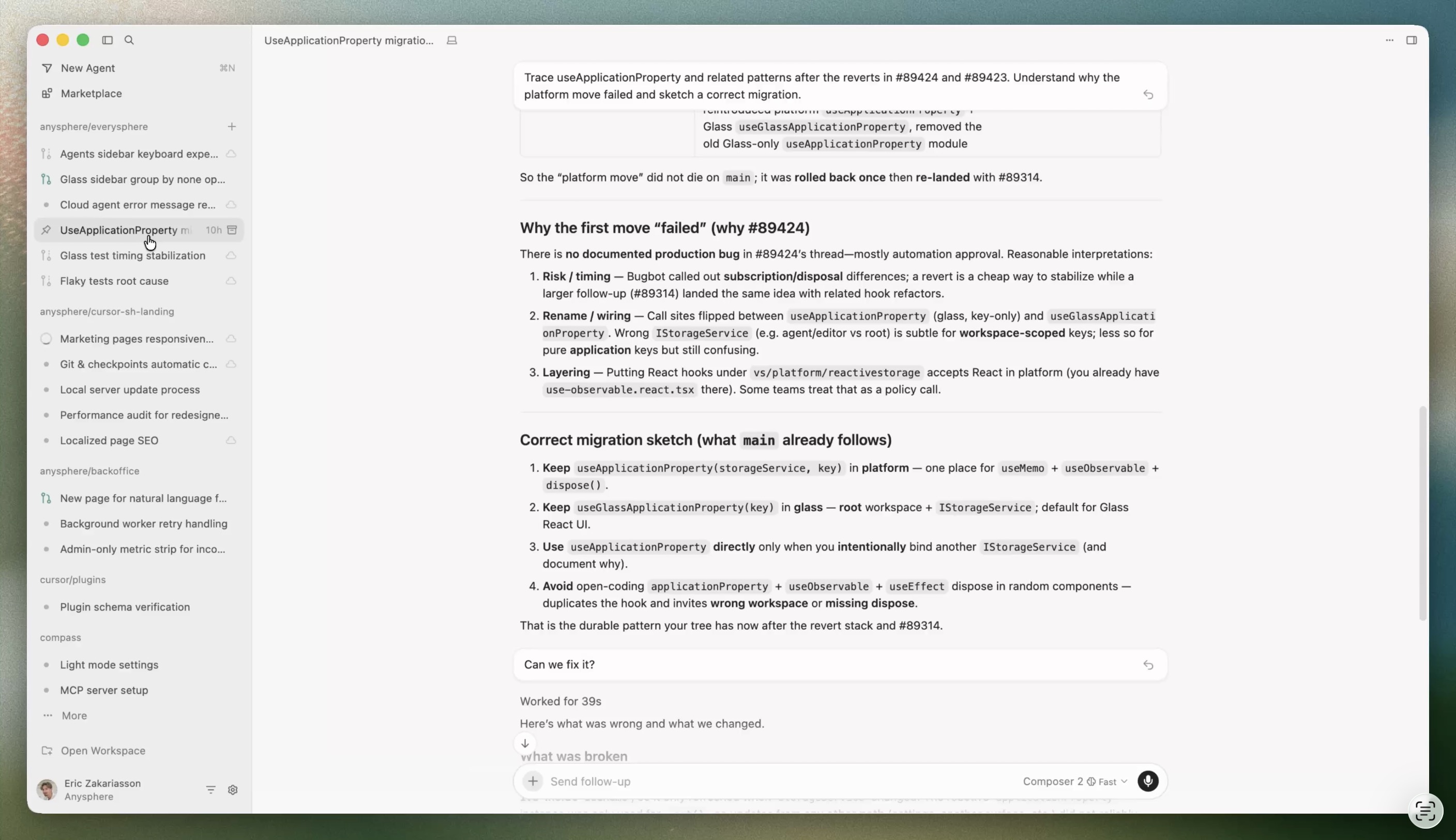
Dude, where’s my code?
The announcement does insist that developers can still view their code, and shows an example…at the very end of the announcement.
In my view, the days of carefully writing and checking your own code are close to over.
2. Many problems can be identified just by looking at output, but many cannot.
When I want to figure out whether my AI’s code is any good, here are my options:
- Scrutinize the output, and see if it passes the smell test. This is part of why I believe strongly in verification-first analysis, in which you write down what “good” output would look like before you press enter, so that you can be a more impartial reviewer once the work is done (when you’ll obviously want to declare success);
- Set up tests, and see if they pass. When working on the policymaker-oriented MCP server, I collaborated with AI to build a whole test suite of potential policymaker questions, along with what the characteristics of a correct answer would look like for each. Then, whenever Claude declared victory on its next feature, I could run it against this test suite and see whether my tool was returning good, defensible, correct answers to the types of questions I envisioned going into it. This is incredibly useful, and par for the course in most software development. It’s also pretty darn time-consuming, even if an agent is building it!
- Read the !#@$ing code, and see if it makes sense. Yes, reader, even though I don’t think anyone will be actually coding in one year’s time, I do still think there will be value in code literacy. First, this is often a much quicker way to figure out what the agent did than reading sets of outputs and validating them against your plan, or setting up evals and running each code change through them. Second, there are types of errors that are easy to find in the code and hard to find in the outputs. For example, if you have a regression specification with fixed effects, it is easier to check that your code specified those FEs correctly than to see whether the regression output (or secondary tables) could plausibly represent the results of a regression with FEs in that context.
A problem that I (and several colleagues) are really struggling with now is whether #3 is worth the cost for the kinds of students we teach. I think students of computer science or data science will still need to be able to interpret code in the immediate future. But if most of my students will not be interacting much with code in the world, nor will they be taking higher-level analysis courses related to coding, is the 30-50% of their time they would spend in my course learning the ins and outs of R or Python worth the ability to catch the types of errors I described above?
3. The more you know about the project and the code, the better the output
Those skeptical of generative AI’s ability to do “real” work often point to hallucinations as a fundamental unresolved issue. I think this problem is largely a non-issue with code, because the code is immediately run and fails to do so if the functions or variables are made up. However, coding agents do make what we would call “mistakes”: misunderstanding what the user (me) is asking, making assumptions about the goals of the project, or over-simplifying tasks that require more thought and care.
The problem is that, if you don’t know what the code is doing, it is extremely difficult to distinguish between a completely trivial error and a load-bearing one.
This can be offset somewhat by the use of review agents; in short, when your agent is done with a particular task, you can have a second, independent agent scrutinize the code and provide feedback. Interestingly, OpenAI recently released a Codex plugin for Claude Code, which includes skills such as /codex:review, where a Codex agent runs through your changes and provides a report, and even /codex:adversarial-review, in which the agent scrutinizes not just the code but the architecture and tradeoffs hidden in your code. These code review agents can be super helpful at identifying errors that your main agent made.
The (second) problem is that, if you don’t know what the code is doing, you are left with two competing agents making the case for one of several options, and have no real way of deciding which is the better choice if you lack the expertise to weight the tradeoffs.
Now maybe this problem is a non-issue, because coding agents will get so good that they won’t need our input. But in the projects I’ve worked on in the past few months, there are a whole host of choices that don’t have a clear “right” answer (though they certainly have wrong answers). Thus, these design choices remain, for now, judgment calls that take into account a whole lot of stuff outside of the context window of your agent (again, for now!).
4. A Cautionary Tale: Debt, both Technical and Cognitive, accrues very quickly
Current frontier models are exceptionally good at writing code that accomplishes a particular goal you give them; they are less good at making high-level architectural decisions in the moment and working toward a goal that preserves that architecture. I learned this the hard way when I vibe-coded the class transcript feature of PingPong, and verified that it worked splendidly with my own class transcripts. Unfortunately, when I showed the result to our developer, they very politely told me that I had both shown that the feature I aimed to build was possible, and that I would have to start over.
In short, I had jerry-rigged my feature by slotting it into an existing part of PingPong that did work, but that would cause us lots of headaches down the road. If I had continued to build on top of this, the technical debt of failing to build the necessary infrastructure around my feature would be felt almost immediately in the form of very high token usage, inconsistent retrieval from the transcripts, and pretty slow response times.
So for my second attempt, I worked with Claude and the developer to build out a plan for what the feature might look like when properly implemented. We had a few iterations; I pulled in other review agents to scrutinize the plan itself, and we ended up with a much more coherent plan that I could give to Claude to build.
I was quite happy with this result and set my agents to work on building the features, working on other things as they built. There were a few questions along the way that I attempted to answer, but it more or less went smoothly. I then called my review agents to do code review and had them iterate a few times.
After the second round of code review, I realized that I had no idea what the agents were talking about anymore.
What had happened was that the distance between what the AI was doing and my understanding of what it was doing had grown too large for me to handle. At that point, I was essentially a monkey at a computer saying “yes” as my competing agents worked on the problem together. I was deep in cognitive debt, with little chance of paying back what I owed.
Luckily, I was almost at the end of that development cycle, and I was able to ask our developer to do a more careful review. At this point, I still do not know a number of pretty important things about what my agents did, but our developer does, and I’m grateful for that.
I guess expertise still does matter.
For now?
The Conundrum
So here I am, trying to figure out how much coding to teach my students. I cannot help but think that they should be able to read code, or at least parse out what particular segments of a large script are doing. It’s just too easy to lose your grip on what’s actually happening if you look at a wall of code and have absolutely no idea what it’s getting at. But that requires time, time that I could otherwise spend teaching them to distinguish between descriptive and causal claims, or think about how a cohort might change over time which will affect their interpretation of their analysis, or recognize base rate neglect in practice!
One thing I have started to feel these past few months is that the phrase “the language of the future isn’t Python; it’s English (or whatever other language you’d like)” is a real over-simplification. Whether it’s me doing the translating or the LLM, a translation from words to code syntax is going to happen no matter what. Indeed, the greatest trick Cowork ever pulled was convincing us that, when it does our work for us, it’s doing it in the same we do. Even if it looks like Claude is editing your PowerPoint like a human would, if you look under the hood it’s writing dozens of little scripts to manipulate and repackage different parts of each slide. Code will remain a fundamental part of how analytic work happens; it just won’t be written by a person. And that’s what makes this pedagogical decision so hard.