While discussing research workflows with colleagues, I’ve been surprised to hear that many get the full text of a journal article by coming across an article, navigating to their school library website, searching for the journal under E-Resources, clicking on the journal link, digging down to the article of interest, and downloading it.
It doesn’t have to be this way (usually).
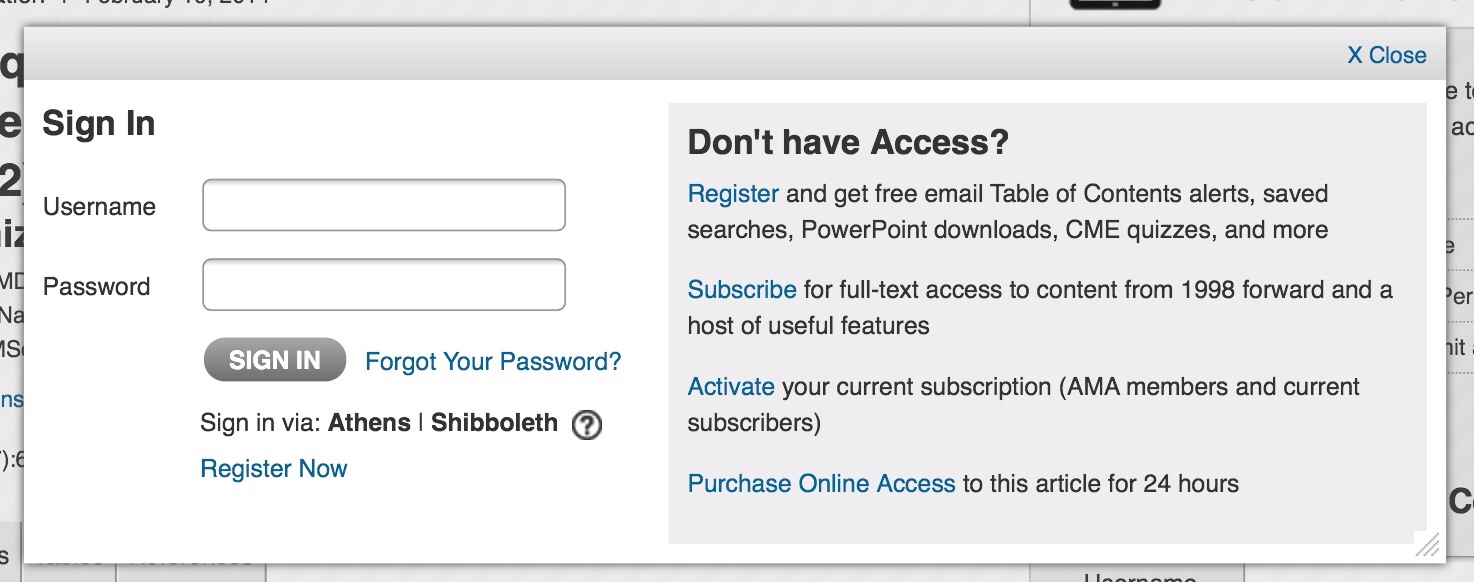
In most cases, links to journal pages through your library’s website are identical to their ordinary link + a suffix (called an EZproxy) that validates your school credentials to check if you have access. Thus, instead of:
http://jama.jamanetwork.com/journal.aspx
Your library’s link will look something like:
http://jama.jamanetwork.com.ezp-prod1.hul.harvard.edu/journal.aspx
Your browser can make this change through what’s called a ‘bookmarklet,’ a bookmark that, when clicked, does something with the existing URL in your browser. For my case, creating a bookmark with the following script as its content will redirect a journal’s site through my school library:
javascript:void(location.href='http://ezp-prod1.hul.harvard.edu/login?url='+location.href)
Alternatively, you can simply drag this EZproxy link into your browser bar.
Here’s a list of different schools’ EZproxy URLs. Edit the code above by replacing http://ezp-prod1.hul.harvard.edu/login?url= with your school’s URL.
In practice, this means that if you click this after trying to access a full PDF:
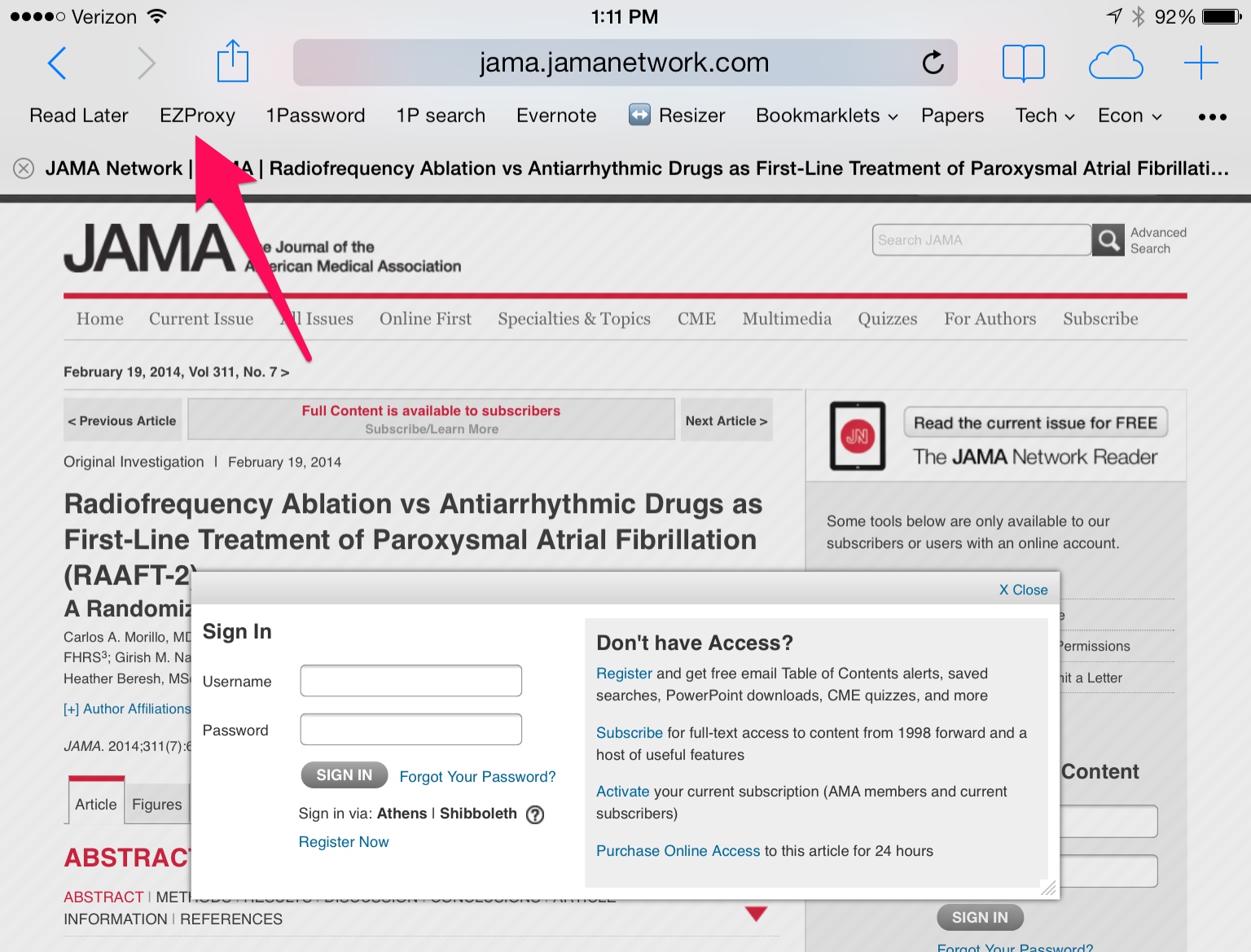
You get this:

Now, the caveat: this will not work for certain journals1. This may be because your school accesses that journal through some larger database, in which case you may have to go back to your library website, like an animal. But this works for me most of the time; hope you find it useful.
-
Note that this may simply be because your school doesn’t have access to that journal. Ugh, I know. ↩